Blockchain Infrastructure Deployment: Nodes, RPC, Indexing
Subgraph fell at 3:47 AM. By morning users saw outdated balances, transactions "hung" in the UI, support received 47 tickets in an hour. Cause: the handler in the subgraph failed on a transaction with a non-standard event log — and the entire index stopped. We have encountered such situations dozens of times. Our experience shows: blockchain infrastructure does not forgive gaps in observability. Guaranteeing uptime without multi-layered monitoring and fault-tolerant architecture is impossible. Over 8 years working with Ethereum, Polygon, and Solana, we have developed an approach that allows predictable deployment of infrastructure of any scale — from a single node to a multichain grid with dozens of subgraphs.
RPC Layer Architecture
Every dApp interaction with the blockchain goes through RPC — the JSON-RPC API provided by a node. Three options:
Managed providers — Alchemy, QuickNode, Infura, Ankr. Minimal operational costs, SLA, built-in monitoring. Limits: rate limits (Alchemy Free: 300 RU/sec), vendor lock, potential downtime during provider incidents. For most projects — the right choice at the start.
Self-owned nodes — full control, no rate limits, no third-party dependence. Cost: archive Ethereum node requires 2.5–3TB SSD, a strong server, and DevOps support. Sync from scratch on Ethereum via Geth/Nethermind — 3–7 days. Justified under high load or latency requirements.
Hybrid — self-owned node as primary, managed provider as fallback. Standard for protocols with high TVL. Proper load balancing can reduce costs by 20–30% compared to pure managed setup. Under high monthly request volume, hybrid saves significantly.
| Provider |
Strength |
Limitation |
| Alchemy |
Supernode, Enhanced APIs, webhooks |
Expensive on high-volume |
| QuickNode |
Low latency, multi-chain |
More expensive than Alchemy on basic plan |
| Infura |
Historical reliability |
Rate limits on free, one major incident halted half of DeFi |
| Ankr |
Cheap, 40+ chains |
Less stable |
How to Set Up an RPC Layer Without a Single Point of Failure?
At least two providers, DNS round-robin with health check every 5 seconds, automatic fallback when latency >500 ms. In practice, this gives 99.99% availability during any provider failure. For protocols with high TVL, we recommend a custom HA-proxy (nginx or Envoy) in front of two managed providers.
Why Is a Hybrid RPC Scheme More Cost-Effective Than Pure Managed?
At high request volumes, managed providers can be very expensive; a hybrid using a self-owned node as primary and a managed fallback cuts costs significantly without losing SLA.
Ethereum Node Clients
Execution clients: Geth (most used), Nethermind (C#, fast sync), Besu (Java, enterprise), Erigon (fastest sync, efficient archive mode ~2TB instead of 3TB).
Consensus clients (post-Merge): Lighthouse (Rust), Prysm (Go), Teku (Java), Nimbus (Nim). Each node after The Merge requires a pair of execution + consensus clients.
For DevOps: eth-docker — Docker Compose configurations for all client combinations. Setting up monitoring via Grafana + Prometheus is mandatory; a standard dashboard is available in each client's repository.
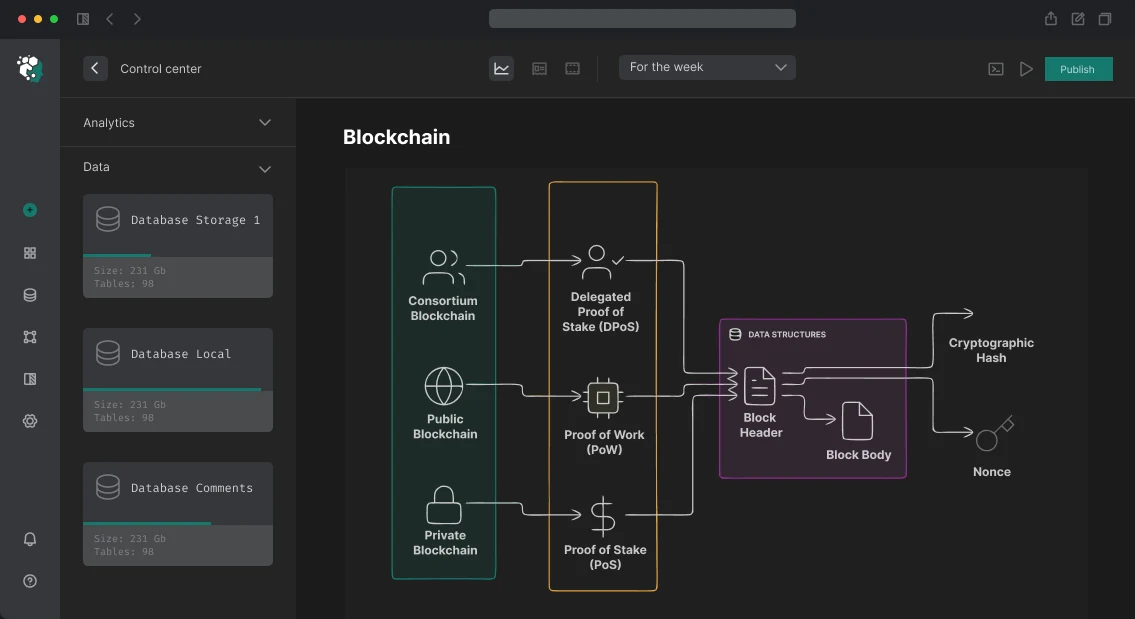
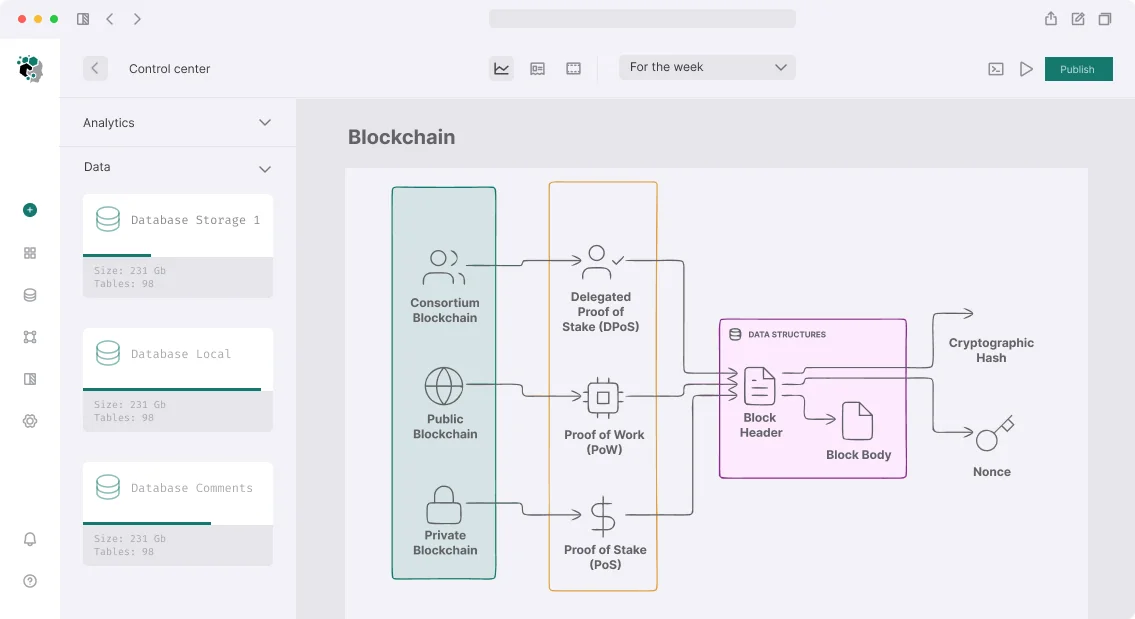
The Graph: Event Indexing
The Graph Protocol — decentralized indexing. A subgraph describes which events from which contracts to index and how to transform them into a GraphQL schema.
Subgraph structure:
-
subgraph.yaml — manifest: contract addresses, startBlock, events to handle
-
schema.graphql — GraphQL schema of entities
-
src/mapping.ts — AssemblyScript event handlers
dataSources:
- kind: ethereum
name: UniswapV3Pool
network: mainnet
source:
address: "0x88e6A0c2dDD26FEEb64F039a2c41296FcB3f5640"
abi: UniswapV3Pool
startBlock: 12370624
mapping:
eventHandlers:
- event: Swap(indexed address,indexed address,int256,int256,uint160,uint128,int24)
handler: handleSwap
AssemblyScript handlers — not TypeScript. No nullable types, no closures, no many standard APIs. An error in the handler stops the subgraph indexing on that transaction. Important: add try-catch for operations that can fail (e.g., store.get() for an entity that may not exist).
How to Avoid Subgraph Indexing Stops?
Graph Node logs are monitored in real-time; on hasIndexingErrors = true an alert fires and an automatic node restart (via systemd or Kubernetes). Typical downtime on error — 150–300 seconds to recover. Additionally, for production we set up a watchdog that restarts Graph Node if subgraph lag exceeds 50 blocks.
Choosing Between Hosted Service and Decentralized Network
Graph Hosted Service (free, centralized) is deprecated in favor of Subgraph Studio + Graph Network. For production: deploy on Graph Network with GRT curation signal — the subgraph gets indexers proportional to curation.
Alternatives to The Graph: Ponder (TypeScript, self-hosted, easier to debug), Envio (ultra-fast indexer, supports EVM + non-EVM), Subsquid (TypeScript, own network), Moralis Streams (managed, webhook-based). Our experience shows: for high-load projects with unique logic, Ponder or Envio are more effective — they give full control over the process and do not require GRT tokenomics.
Webhooks and Real-Time Notifications
Alchemy Webhooks and QuickNode Streams allow receiving events in real-time via HTTP webhook or WebSocket. For monitoring addresses, new transactions, mints — this is faster than polling RPC.
Tenderly — platform for monitoring and alerts. You can set up an alert for a specific contract event, balance change, function call with certain parameters. Transaction simulation via Tenderly API is invaluable for debugging.
Monitoring and Observability
Minimum monitoring stack for a protocol:
On-chain: OpenZeppelin Defender Sentinel — watches contract events, triggers webhook or Autotask when conditions are met. Forta Network — community-maintained bots detect anomalies (large withdrawals, flash loans, governance attacks).
Infrastructure: Grafana + Prometheus for nodes, Datadog or Grafana Cloud for managed metrics. Alerts on: node is 10+ blocks behind, RPC latency >500ms, subgraph lag >100 blocks.
Uptime: Better Uptime or PagerDuty on RPC endpoint and subgraph health endpoint (The Graph provides _meta { hasIndexingErrors, block { number } }).
Why Is Monitoring Without Tenderly Insufficient?
Tenderly provides transaction simulation and detailed traces — critical for debugging subgraph and smart contract errors. Forta focuses on network anomalies, not your infrastructure. The combination of Tenderly plus a custom Grafana dashboard covers 90% of incident scenarios.
Multichain Infrastructure
A protocol on 5 chains = 5 separate RPC endpoints, 5 subgraphs, 5 monitoring configs. Manageable but requires deployment automation.
For subgraph multi-network deployment: graph deploy --network mainnet, graph deploy --network arbitrum-one etc. with a unified codebase and network-specific addresses in separate config files.
Chainlink CCIP and LayerZero for cross-chain messaging require monitoring of both chains and transactions on intermediate relayers. A reorg on the source chain after a confirmed mint on the target chain is a classic bridge problem. Solution: wait for finality (on Ethereum ~15 minutes after Merge for economic finality) before confirming on the target chain.
Infrastructure Setup Process
- Audit current stack — determine chains, request volume, latency and availability requirements.
- Architecture design — select providers, load balancing, redundancy.
- Subgraph development — manifest → schema → handlers → testing on local Graph Node → deploy to testnet → mainnet.
- Monitoring configuration — Tenderly alerts, Grafana dashboard, PagerDuty integration.
- Documentation and runbook — what to do when: subgraph falls behind, RPC downtime, node desync.
- Handover to operations — team training, access transfer, first month support.
What's Included
- Deployment of managed or self-hosted Ethereum, Polygon, BNB Chain nodes
- RPC layer setup with primary/fallback and load balancing
- Subgraph development and deployment for your protocol
- Monitoring connection (Tenderly, Grafana, alerts)
- Runbook and operations documentation
- Team training (up to 4 hours online)
- 30-day support after delivery
Timeline
| Task |
Duration |
| RPC and basic monitoring setup |
1–2 weeks |
| Subgraph for one protocol |
2–4 weeks |
| Self-hosted node with monitoring |
2–3 weeks |
| Full infrastructure (multi-chain, monitoring, runbooks) |
6–10 weeks |
All projects are managed in a GitHub/GitLab repository with CI/CD; configuration code stays with you. Order infrastructure deployment — we'll show how to cut costs by 20–30% without losing reliability. Get a consultation — we'll demonstrate how we deployed infrastructure for a protocol with large TVL on Ethereum and Arbitrum. Contact us.